Food and Agriculture Organization of the United Nations (2025) – with major processing by Our World in Data. “Chicken meat production – UN FAO” [dataset]. Food and Agriculture Organization of the United Nations, “Production: Crops and livestock products” [original data]. Retrieved February 18, 2026 from https://archive.ourworldindata.org/20260119-235736/grapher/chicken-meat-production.html (archived on January 19, 2026).
# Loading used librarieslibrary(ggplot2)library(maps)library(countries)library(dplyr)
Attaching package: 'dplyr'
The following objects are masked from 'package:stats':
filter, lag
The following objects are masked from 'package:base':
intersect, setdiff, setequal, union
library(here)
here() starts at C:/Users/marco/Documents/marcoreina-portafolio
# Loading data and exploring variablesoriginal_data <-read.csv(here("presentation-exercise/chicken-meat-production/chicken-meat-production.csv"))str(original_data)
region Code Year Chicken.meat.production
Length:14385 Length:14385 Min. :1961 Min. : 0
Class :character Class :character 1st Qu.:1977 1st Qu.: 4300
Mode :character Mode :character Median :1993 Median : 40589
Mean :1993 Mean : 1421667
3rd Qu.:2008 3rd Qu.: 373800
Max. :2023 Max. :126530270
# Determining if entity is a country nameoriginal_data$is_country <-is_country(x = original_data$region)# Adding ISO code for all the countriesoriginal_data$iso_code <-country_name(x= original_data$region, to="ISO3")
Some country IDs have no match in one or more of the requested country naming conventions, NA returned.
Multiple country IDs have been matched to the same country name.
Set - verbose - to TRUE for more details
# Creating bins for chicken production: code fine-tuned with ChatGPTbreaks_prod <-c(0, 100000, 200000, 500000, 1000000, 2000000, 5000000, 10000000, 100000000)# Mutating data to include bins: code fine-tuned with ChatGPToriginal_data <- original_data |>mutate(prod_bin =cut( Chicken.meat.production,breaks = breaks_prod,include.lowest =TRUE,right =FALSE ) )# Changing bins names to categories: code fine-tuned with ChatGPTlevels(original_data$prod_bin) <-c("0 – 100k t","100k – 200k t","200k – 500k t","500k – 1M t","1 – 2M t","2 – 5M t","5 – 10M t","> 10M t")# Creating clean data vector and exploring variablesclean_data <-subset(original_data, is_country ==TRUE)str(clean_data)
region Code Year Chicken.meat.production
Length:11432 Length:11432 Min. :1961 Min. : 0
Class :character Class :character 1st Qu.:1977 1st Qu.: 2700
Mode :character Mode :character Median :1994 Median : 19084
Mean :1993 Mean : 274513
3rd Qu.:2009 3rd Qu.: 108000
Max. :2023 Max. :20197090
is_country iso_code prod_bin
Mode:logical Length:11432 0 – 100k t :8450
TRUE:11432 Class :character 100k – 200k t: 911
Mode :character 200k – 500k t: 861
500k – 1M t : 558
1 – 2M t : 404
2 – 5M t : 146
(Other) : 102
# Creating 2023 dataset, just to mimic the first plot showndata_2023 <-subset(clean_data, Year ==2023)
# Loading world map and removing Antarcticaworld_map <-map_data("world") %>%filter(region !="Antarctica")# Adding ISO code for all the countriesworld_map$iso_code <-country_name(x= world_map$region, to="ISO3")
Some country IDs have no match in one or more of the requested country naming conventions, NA returned.
Multiple country IDs have been matched to the same country name.
Set - verbose - to TRUE for more details
# Merging dataframes based on the ISO code per countrymap_2023 <-left_join(world_map, data_2023, by ="iso_code")
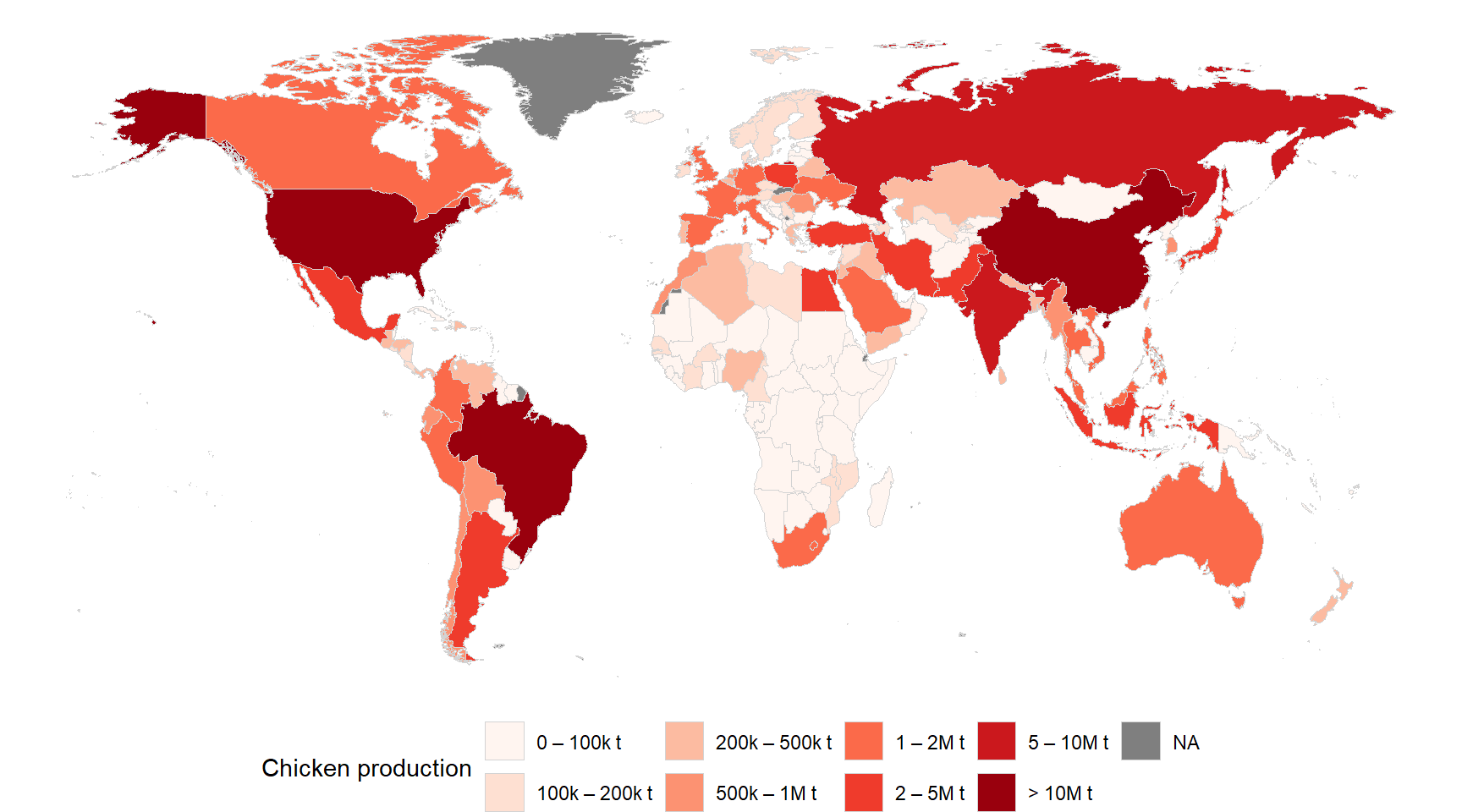
Chicken Production around the world 2023 (Recreated from FAO data)
# Recreating plot for 2023: code fine-tuned with ChatGPTplot_2023 <-ggplot(map_2023, aes(long, lat, group = group, fill = prod_bin)) +geom_polygon(color ="lightgrey", linewidth =0.1) +labs(fill ="Chicken production" ) +theme_void() +theme(legend.position ="bottom") +scale_fill_manual(values =c("#FFF5F0", "#FEE0D2", "#FCBBA1", "#FC9272", "#FB6A4A", "#EF3B2C", "#CB181D", "#99000D") )plot_2023
Creating a table using this same information
ChatGPT prompt: “I want to make an interactive table for chicken consumption from around the world that integrates some graphs within the table, i have information from 1961 to 2023”
Warning: Returning more (or less) than 1 row per `summarise()` group was deprecated in
dplyr 1.1.0.
ℹ Please use `reframe()` instead.
ℹ When switching from `summarise()` to `reframe()`, remember that `reframe()`
always returns an ungrouped data frame and adjust accordingly.
`summarise()` has grouped output by 'region'. You can override using the
`.groups` argument.
ChatGPT response:
reactable( table_data, columns = list( country = colDef(name = “Country”),
latest_2023 = colDef( name = “Consumption (2023)”, format = colFormat(digits = 1) ),
Table shows the 2023 production and the change percentage compared to 2022. Conditional formatting is shown as black for for -5% to 5%, green for +5% and above, red for -5% and under. Table can be searched and sorted.