Project info
Identifying Key Metadata Predictors of Salmonella AMR Genotypes through Machine Learning
Author
- Marco Reina\(^{1}\)
Author affiliations
- Department of Poultry Science, University of Georgia, Athens, GA, USA.
\(\land\) Corresponding author: marco.reinaantillon@uga.edu
\(\dagger\) The author utilized AI tools, specifically Qween and Gemini, for code troubleshooting; and the use of Copilot to refine the English writing.
Summary/Abstract
In the United States, nontyphoidal Salmonella causes an estimated 1.35 million infections annually, with resistant strains associated with increased hospitalization rates and adverse clinical outcomes. Surveillance systems such as the National Antimicrobial Resistance Monitoring System (NARMS) and NCBI Pathogen Detection generate large-scale genomic and metadata resources that enable data-driven approaches to AMR risk prediction. This project leverages machine learning to predict AMR prevalence in Salmonella isolates using readily available metadata, which included isolation source, serotype, and temporal variables. This approach is helpful because expedites the analysis and offers a first quick screening before obtaining the whole-genome sequencing data. Using a curated dataset of 245,772 isolates from the NCBI Pathogen Detection repository, a binary outcome variable model was engineered, which helps indicating presence or absence of resistance to at least one antimicrobial class. A random forest classifier was implemented via the tidymodels framework, with model performance evaluated through 10-fold cross-validation and a held-out test set. Results indicate strong discriminative ability (ROC AUC = 0.825), high specificity (97.7%), and moderate sensitivity (35.2%), reflecting the inherent class imbalance in surveillance data where non-resistant isolates predominate. Variable importance analyses identified isolation source and top-20 serovars (e.g., I 4,[5],12:i:-, Infantis, Typhimurium) as key predictors of AMR status. These findings support the feasibility of using metadata-driven models for rapid, scalable AMR risk stratification in food safety and public health surveillance contexts.
SUPPLEMENT: Complete iterative process of the project available here
Introduction
Antimicrobial resistance (AMR) is an escalating global public health threat, projected to contribute to 10 million deaths annually by 2050 if current trends continue (O’Neill, 2016; WHO, 2024). Foodborne pathogens, particularly nontyphoidal Salmonella, play a central in harboring and dissimination of resistant genes from agricultural and environmental reservoirs, allowing Salmonella successfully reach human populations (CDC, 2024). In the United States alone, it is estimated that Salmonella causes around 1.35 million illnesses each year, and infections involving resistant strains are associated with longer durations of illness, higher rates of hospitalization, and increased treatment complexity (CDC, 2024; WHO, 2022).
Large-scale surveillance initiatives, like the National Antimicrobial Resistance Monitoring System (NARMS) and the NCBI Pathogen Detection project have generated extensive repositories of bacterial isolate metadata, including source of isolation, serotype, collection date, and geographic origin (CDC, 2026; NCBI, 2026). While whole-genome sequencing offers high-resolution insights into resistance mechanisms, genomic data are not always available in real-time surveillance or resource-limited settings. In contrast, metadata like source and month of collection are routinely collected and immediately accessible. Additionally, serovar could be determine through different faster methods like serovar-specific qPCR screening, allowing this additional variable to be available before obatining the computed serovar preduiction by whole genome sequencing. This raises an important question: Can readily available isolate metadata alone support accurate, scalable prediction of AMR status to inform proactive public health interventions?
The objective of this project is to develop and evaluate a machine learning model that predicts antimicrobial resistance prevalence in Salmonella isolates using only metadata variables, specifically isolation source, top serovars, and temporal indicators, like collection month. By developing a random forest classifier within the tidymodels framework (Kuhn & Wickham, 2020), this work aims to demonstrate the feasibility of metadata-driven risk stratification as a complementary tool for food safety surveillance and early-warning systems. We define the “feasibility” of this as the model’s capacity to provide a rapid and lower cost screening with high specificity (the ability to accurately classify isolates as resistant or susceptible >95% of the time).
General Background Information
Antimicrobial resistance in Salmonella most frequently involves five clinically important drug classes: β-lactams (including extended-spectrum cephalosporins), fluoroquinolones, aminoglycosides, tetracyclines, and sulfonamides/trimethoprim. Resistance to β-lactams is primarily mediated by β-lactamase enzymes (e.g., TEM, SHV, CTX-M, and carbapenemases like KPC), with over 1,170 distinct genes identified to date. Fluoroquinolone resistance typically arises from chromosomal mutations in gyrA and parC or plasmid-mediated qnr genes. Aminoglycoside resistance commonly involves enzymatic modification via aminoglycoside-modifying enzymes (e.g., aac, aph, aad genes). Tetracycline resistance is frequently conferred by efflux pumps (tetA, tetB) or ribosomal protection proteins (tetM).
However, Salmonella could be resistant to more than one drug. Multidrug resistance (MDR), which is defined as non-susceptibility to ≥3 antimicrobial classes, is increasingly prevalent in nontyphoidal Salmonella and poses significant treatment challenges. MDR often arises through co-selection mechanisms, where resistance genes cluster on mobile genetic elements (plasmids, integrons, transposons), enabling simultaneous acquisition of resistance to multiple drug classes. Cross-resistance occurs when a single mechanism confers resistance to multiple antimicrobials within or across classes; for example, efflux pumps like AcrAB-TolC can export diverse compounds including fluoroquinolones, β-lactams, and biocides. The emergence of extensively drug-resistant (XDR) strains (resistant to ≥5 classes) has been documented in serovars such as Typhimurium and Infantis, often linked to plasmid acquisition.
Serovar and isolation source are considered among the strongest predictors of AMR status in Salmonella surveillance data. Certain serovars exhibit characteristic resistance profiles: for instance, Typhimurium and 4,[5],12:i:- are frequently associated with the ACSSuT MDR phenotype (ampicillin, chloramphenicol, streptomycin, sulfonamides, tetracycline), while Heidelberg and Infantis increasingly harbor extended-spectrum cephalosporin resistance. Isolation source further refines risk prediction: isolates from poultry and retail meats show higher odds of resistance to tetracyclines and aminoglycosides compared to human clinical isolates, reflecting antimicrobial use patterns in agricultural settings. Metadata capturing serovar and source therefore provide actionable, low-cost proxies for AMR risk stratification in surveillance contexts.
A particular concern has emerged from serovar Infantis, because it has a multidrug-resistant clone of particular concern in poultry production systems has been dissiminated globally. The success of serovar Infantis is largely attributed to the pESI (p_Salmonella_ Infantis) megaplasmid (~280 kb), a conjugative plasmid that carries multiple resistance determinants (e.g., blaCTX-M-65, tetA, sul1, dfrA14), virulence factors (iroN, iss), and heavy-metal resistance genes. Strains harboring pESI exhibit significantly higher resistance to ampicillin, cefazolin, gentamicin, nalidixic acid, trimethoprim-sulfamethoxazole, and tetracycline compared to pESI-negative isolates. Critically, pESI is highly stable and transferable across Salmonella serovars, facilitating rapid dissemination of MDR traits across reservoirs. The global expansion of pESI-positive Infantis underscores the importance of metadata-driven surveillance to detect and track high-risk clones before they cause widespread outbreaks.
Description of Data and Data Source
This project utilizes isolate-level metadata and antimicrobial resistance (AMR) phenotype data from the NCBI Pathogen Detection repository, a centralized platform that integrates genomic sequences, standardized metadata, and AMR annotations from surveillance initiatives including NARMS, GenomeTrakr, and international partners. The complete analytical dataset that it was downloaded, it originally comprised 688,980 Salmonella enterica isolates collected from human clinical cases, food animals, retail meats, and environmental sources across the United States between 2010–2024. For this project this first dataset was labeled as “isolates dataset”.
In addition to isolate dataset, this project incorporates genomic structural data from the NCBI Bacterial Genomes database. While the Pathogen Detection repository focus on surveillance and AMR phenotypes, the Genomes dataset provides a detailed characterization of the physical assembly and annotation metrics for selected Salmonella isolates. This dataset is used to explore the relationship between genome architecture features, and included 33,867 genome. For this project this second dataset was labeled as “genomes dataset”.
Key metadata variables: Isolates dataset
- Isolation source (e.g., human, food, animal, or environmental)
- Collection date (day, month, and year)
- Geographic origin (country)
- Computed antimicrobial resistance genotypes
AMR status was operationalized as a binary outcome: an isolate was classified as “resistant” if it exhibited non-susceptibility to ≥1 antimicrobial class; otherwise, it was classified as “susceptible.” This definition aligns with public health priorities for early detection of any resistance emergence. Data preprocessing included removal of isolates with missing source or serovar information, deduplication of genetically identical isolates from the same source/date, and harmonization of serovar nomenclature.
Key metadata variables: Genomes dataset
- Assembly Stats: Total sequence length and number of contigs (to assess assembly quality and genome size).
- Annotation Metrics: Total gene count, protein-coding gene count, and pseudogene count.
- Assembly Level: Classification of the assembly (e.g., “Complete Genome” vs. “Scaffold”).
- Release Date: The date the genomic annotation was finalized or updated.
Questions/Hypotheses to be addressed
Can readily available metadata variables (isolation source, serovar, and collection month) predict antimicrobial resistance status in Salmonella isolates before obtaining the whole-genome sequencing results?
The central aim of this study is to determine if routinely collected metadata can serve as a reliable proxy for antimicrobial resistance (AMR) status in Salmonella before whole-genome sequencing results are available. The utility of this approach lies not in replacing genomic analysis, but in providing a rapid, lower cost triage mechanism that catches a significant portion of resistant strains days before laboratory confirmation (the ability to accurately “rule-in” resistant cases). This could allow labs to fast-track those specific isolates for immediate phenotypic testing or deeper sequencing, rather than waiting for the entire batch to be processed. It is hypothesized that specific metadata features, such as serotype and isolation source, contain a sufficient biological “signal” to achieve a level of discriminative performance (ROC AUC > 0.80) that could be useful for early risk stratification and laboratory prioritization.
Methods
Data Preparation and Splitting
To prepare the isolates dataset for a final paper-ready version, the raw data from the NCBI Pathogen Detection database was subjected to a rigorous cleaning and filtration pipeline. Initially, the dataset was reduced by removing non-essential technical metadata, such as sequencing platform details and internal laboratory identifiers, to streamline the analysis. The cohort was then geographically and temporally refined using the countries library to standardize locations to ISO3 codes, specifically filtering for isolates originating in the United States between 2021 and 2025. To ensure the study focused on relevant transmission routes, the data was restricted to four primary source categories: animal, environmental, food, and human. A total of 245,772 isolates were obtained after preprocessing. Following data preparation, the dataset was partitioned into training (75%) and testing (25%) subsets using stratified random sampling to preserve the original class distribution of antimicrobial resistance (AMR) status.
In parallel with the isolates dataset, a secondary dataset was curated from the NIH Bacterial Genomes database (“genomes dataset”) to evaluate structural genomic features and their relationship with AMR. The genomic records were filtered to include only the Salmonella genus and streamlined to retain essential structural variables, including total sequence length, contig count, and the counts of total, protein-coding, and pseudogenes. A total of 33,867 genomes of Salmonella enterica were obtained.These records were then intersected with the NCBI Pathogen Detection database using the BioSample ID as a unique key, with a de-duplication step ensuring only the most recent Annotation Release Date was retained for each isolate. To ensure high-resolution structural integrity for the Descriptive Analysis, the final cohort was restricted to isolates designated as “Complete Genomes.” Although this resulted in a high-quality subset of 214 genomes, the extreme reduction in sample size led to the exclusion of these genomic variables from the final Random Forest models to prioritize broader population generalizability.
Feature Engineering and Preprocessing
The outcome variable amr_prevalence was constructed as a binary factor, where “1” indicated resistance to ≥1 antimicrobial class and “0” indicated full susceptibility. Predictor variables were limited to routinely collected metadata: isolation source (Source.type), the 20 most prevalent serovars (top_20, with all others collapsed into an “Other” category), and collection month (sample_month). Categorical predictors were converted to factor type to enable appropriate encoding within the modeling workflow. No additional scaling or transformation was applied.
Model Specification and Training
A random forest classifier was implemented using the ranger engine within the tidymodels framework. The model specification (rf_spec) was defined in classification mode and combined with the preprocessing formula into a unified workflow() object: amr_prevalence ~ Source.type + top_20 + sample_month. The final model was trained on the complete training dataset, while cross-validated performance was estimated using fit_resamples(). Hyperparameters (e.g., number of trees, mtry, minimum node size) were evaluated at predefined values.
Performance Evaluation
Primary evaluation relied on the receiver operating characteristic area under the curve (ROC AUC), which measures discriminative ability across all probability thresholds and is robust to class imbalance. Secondary metrics included accuracy, sensitivity, specificity, and precision, calculated at the default 0.5 probability cutoff. Predicted class labels and probability scores were extracted via predict() with type = “class” and type = “prob”, respectively. A confusion matrix was generated to visualize true/false positive and negative classifications.
Cross-Validation
To evaluate model generalizability and mitigate overfitting, 10-fold cross-validation was performed on the training set using the vfold_cv function. This procedure partitioned the data into ten distinct, non-overlapping subsets to provide a robust estimate of out-of-sample predictive performance. Beyond cross-validation, an honest assessment was conducted using a held-out test set (comprising 25% of the total data) which remained entirely unseen during the model training to ensure an unbiased evaluation of the final model’s accuracy.
Software and Reproducibility
All data manipulation, modeling, and evaluation were performed in R (v4.4.3) using the tidymodels collection (v1.2.0), including rsample for resampling, workflows for pipeline integration, parsnip for model specification, ranger (v0.16.0) for random forest computation, and yardstick for metric calculation. A fixed random seed (set.seed(1234)) was applied prior to data splitting, fold generation, and model training to ensure complete reproducibility. Analysis code and outputs are version-controlled and publicly accessible via the project repository.
Results
Exploratory Data Analysis
We conducted an exploratory analysis of 245,772 Salmonella isolates to characterize trends in antimicrobial resistance (AMR) and genomic architecture. The most critical exploratory results are summarized below.
Isolate Trends and Source Distribution
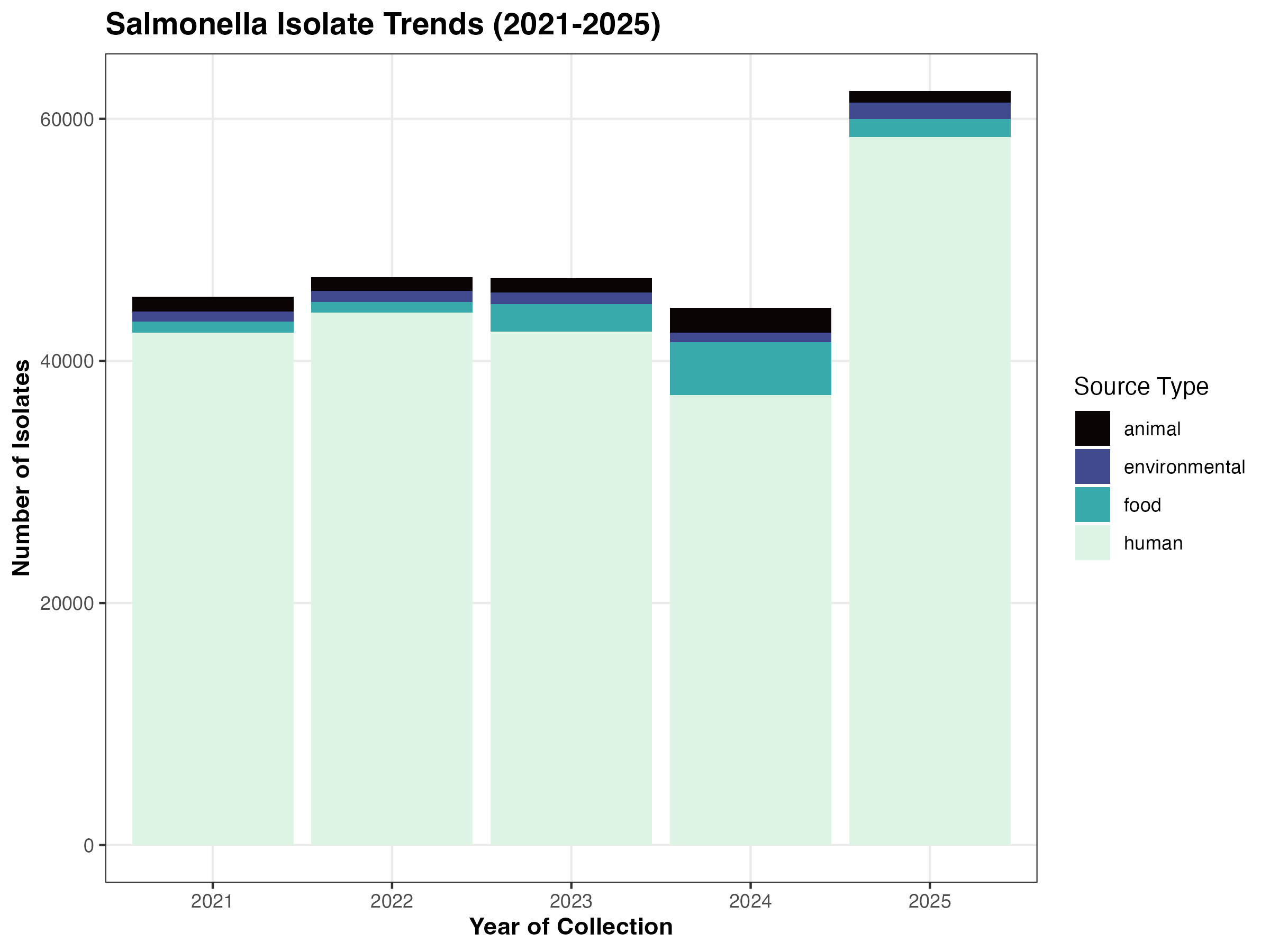
The vast majority of isolates in this dataset originate from human clinical cases, representing a significant focus on clinical surveillance. As shown in Table 1, while clinical samples consistently dominate the dataset, there was a notable increase in food-related isolates during 2023 and 2024.
| Salmonella Isolate Distribution (2021-2025) | |||||
| Annual counts and relative percentages by source type | |||||
| Source Type |
Yearly Distribution [Count (%)]
|
||||
|---|---|---|---|---|---|
| 2021 | 2022 | 2023 | 2024 | 2025 | |
| animal | 1,209 (2.7%) | 1,149 (2.4%) | 1,187 (2.5%) | 2,071 (4.7%) | 977 (1.6%) |
| environmental | 825 (1.8%) | 938 (2%) | 975 (2.1%) | 791 (1.8%) | 1,326 (2.1%) |
| food | 938 (2.1%) | 833 (1.8%) | 2,275 (4.9%) | 4,359 (9.8%) | 1,500 (2.4%) |
| human | 42,314 (93.4%) | 44,015 (93.8%) | 42,417 (90.5%) | 37,171 (83.7%) | 58,502 (93.9%) |
| Data source: NCBI Pathogen Detection Database. | |||||
Visualizing Source Dynamics
The temporal distribution of isolates across different sources is visualized in Figure 1. While raw counts are highest in human sources, the data reveals a significant class imbalance across all categories. This distribution underscores a challenge for the predictive model, as the majority of samples are collected through routine clinical surveillance.
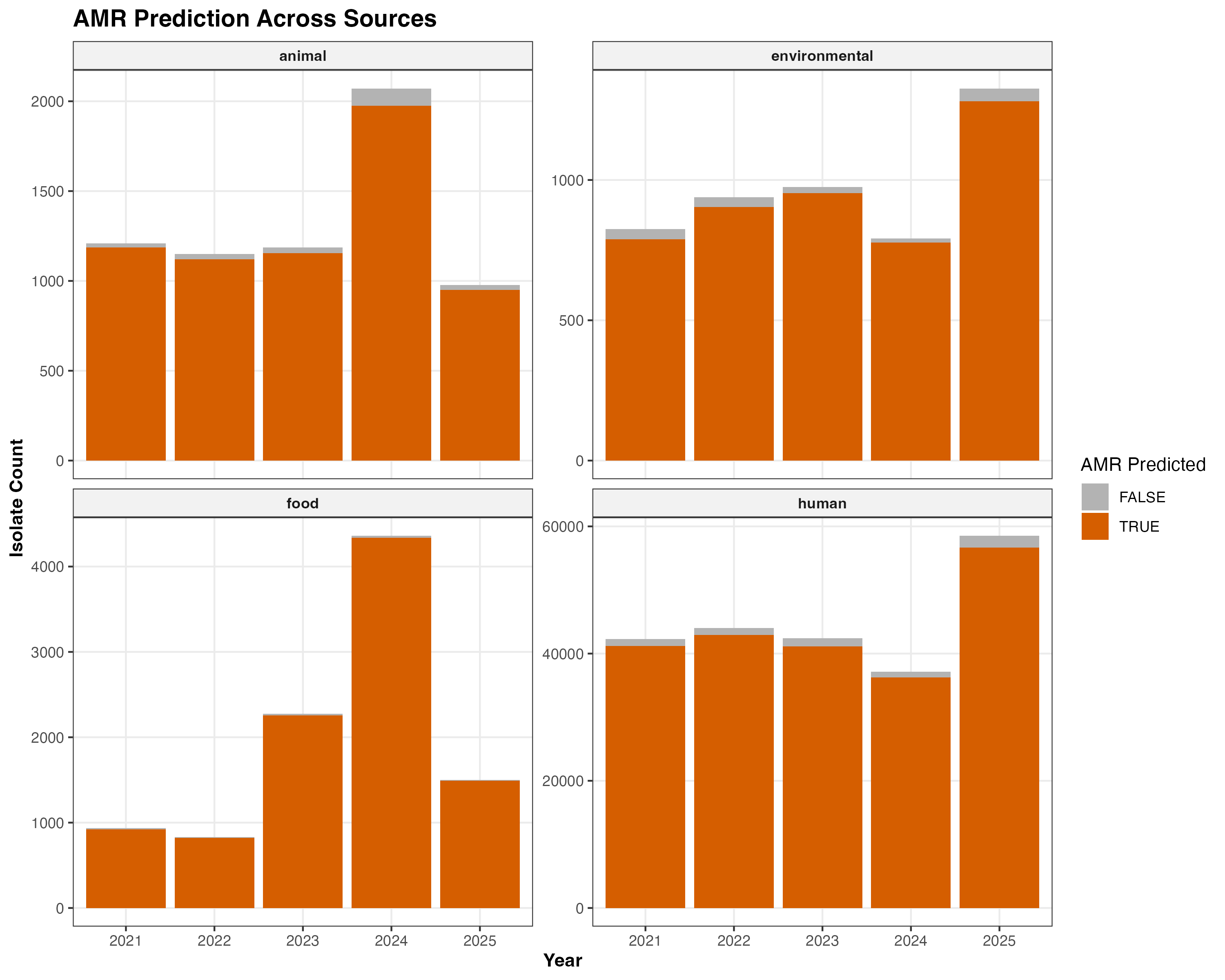
Visualizing AMR Dynamics per source
The analysis of Salmonella isolates reveals a consistent presence of predicted antimicrobial resistance genes across all investigated categories. As shown in Figure 2, while the dataset is heavily weighted toward human clinical samples (comprising over 90% of the total isolates), the proportion of isolates with predicted AMR remains remarkably high, approximately 97.3%, regardless of the source. However, in consequent steps, this trend is shown to be mostly led by Efflux pumps, that were excluded from this analysis due to it’s high prevalence.
Genomic Structure Analysis
In addition to the primary metadata analysis, a secondary dataset comprising high-quality Salmonella genomes was initially processed to evaluate structural features such as genome length, contig counts, and protein-coding genes. However, this dataset was ultimately excluded from the final predictive modeling phase. The decision to omit these genomic dataset was driven by the significant reduction in sample size that occurred during the intersection of the two databases, which would have compromised the model’s ability to generalize across the broader population. Consequently, this study focused exclusively on the metadata features available from the “isolates dataset” to ensure a robust and scalable assessment of AMR trends.
Our Exploratory Analysis confirmed a strong correlation (\(r \approx 0.90\)) between genome length and protein-coding genes, while pseudogene counts appeared to be independent of these structural metrics.
| Correlation Matrix of Genomic Features | |||||
| Pearson correlation coefficients (r) for _Salmonella_ genomes | |||||
| Genomic Feature | Length | Contigs | Total Genes | Protein Coding | Pseudogene1 |
|---|---|---|---|---|---|
| Length | 1.000 | 0.180 | 0.896 | 0.858 | 0.026 |
| Contigs | 0.180 | 1.000 | 0.406 | 0.306 | 0.226 |
| Gene.Total | 0.896 | 0.406 | 1.000 | 0.898 | 0.171 |
| Protein.coding | 0.858 | 0.306 | 0.898 | 1.000 | −0.273 |
| Pseudogene | 0.026 | 0.226 | 0.171 | −0.273 | 1.000 |
| 1 Note the low correlation between Pseudogenes and other features. | |||||
Descriptive analysis
Patterns of AMR Class Prevalence and Co-occurrence
SUPPLEMENT: Complete Descriptive analysis here
A critical step in our descriptive analysis was the characterization of clinically relevant resistance classes. As noted in our Complete Descriptive analysis (supplement), multidrug efflux pumps were excluded from this specific characterization due to their ubiquitous presence (>96% prevalence) across the dataset, which tends to obscure phenotypic resistance trends.
Predominant Resistance Classes
Beyond efflux-mediated mechanisms, Tetracycline, Aminoglycoside, and Sulfonamide resistance emerged as the most prevalent classes (Table 3). These three classes alone account for the majority of the non-intrinsic resistance detected, suggesting a stable reservoir of these genotypes within the Salmonella population.
| Prevalence of Clinically Relevant AMR Classes | ||
| Excluding Efflux Pumps; (n = 245,772 isolates) | ||
| Antimicrobial Class | Isolate Count | Prevalence (%) |
|---|---|---|
| Tetracycline | 26,572 | 10.8 |
| Aminoglycoside | 24,171 | 9.8 |
| Sulfonamide | 20,618 | 8.4 |
| Beta_lactam | 17,522 | 7.1 |
| Phenicol | 10,132 | 4.1 |
| Quinolone | 8,535 | 3.5 |
| Trimethoprim | 8,131 | 3.3 |
| Fosfomycin | 6,015 | 2.4 |
| Macrolide | 3,377 | 1.4 |
| Lincosamide | 653 | 0.3 |
| Rifamycin | 556 | 0.2 |
| Bleomycin | 542 | 0.2 |
| Colistin | 485 | 0.2 |
| Gentamicin | 53 | 0.0 |
| Streptothricin | 33 | 0.0 |
| Glycopeptide | 1 | 0.0 |
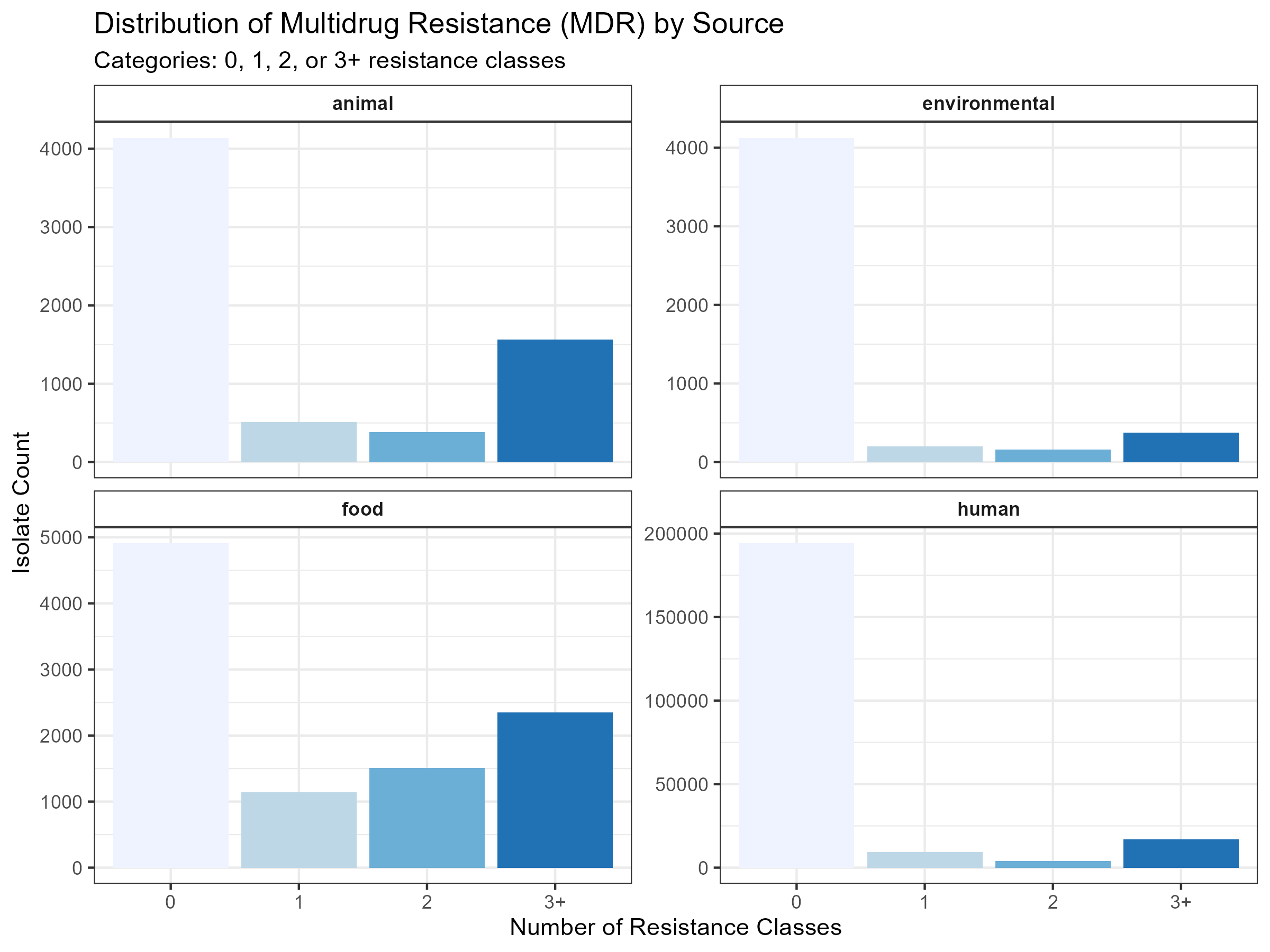
Multidrug Resistance (MDR) by Source
The distribution of multidrug resistance (defined here as resistance to 3 or more classes) showed distinct patterns across isolation sources (Figure 3). While the raw volume of isolates is highest in human clinical samples, a higher proportion of MDR isolates was observed in animal and food-related sources. This suggests that while human surveillance captures more total resistance, the complexity of resistance profiles may be more pronounced in agricultural and production environments.
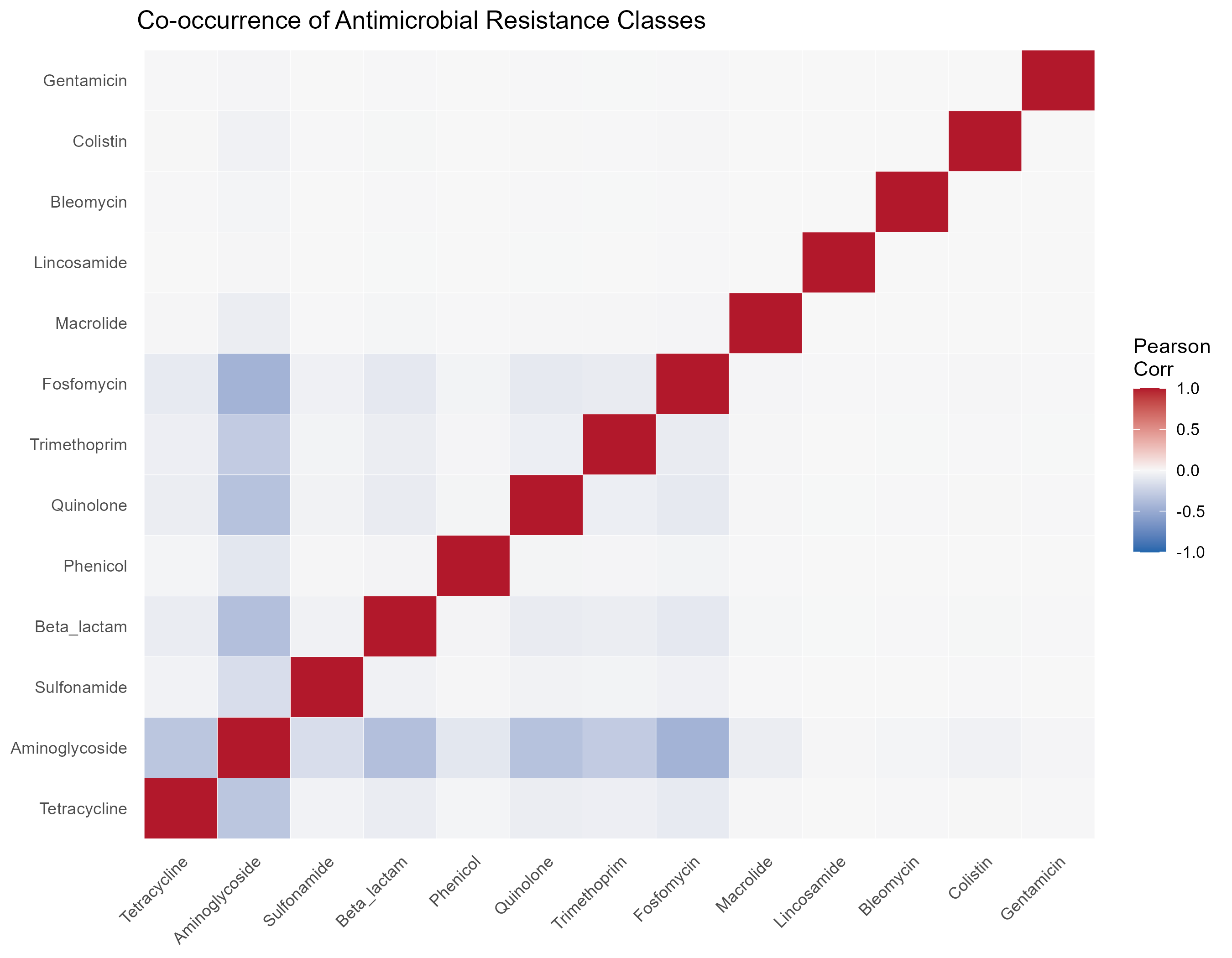
Co-occurrence and Correlation
To understand the underlying structure of these resistance profiles, we calculated the co-occurrence of AMR classes using Pearson correlation (Figure 4). Interestingly, our results highlight a negative correlation between Aminoglycosides, Tetracyclines, Beta_lactam, Trimetroprim, and Fosfomycin, these results are suggesting that these resistance genotypes are largely mutually exclusive and may emerge in distinct sub-populations of Salmonella. While the majority of the interactions are mostly neutral.
Full analysis
First, a Linear Model was constructed to understand genome structure using the dataset “genomes”. Nonetheless, this line of analysis was not incorporated in the manuscript due to overfitting and possible leakage in the model. The linear model analysis is included in the project website as supplementary material.
Second, a baseline Logistic Regression model was constructed and achieved comparable predictive performance (AUC = 0.822) to the Random Forest approach. However, Random Forest was selected as the primary model for two key reasons:
Non-linear interaction capture: Random Forests naturally model complex, non-additive relationships between predictors (e.g., isolation source × serotype) without requiring manual specification of interaction terms.
Robustness to feature expansion: As additional metadata variables are incorporated, Random Forest provide greater resistance to overfitting and more stable predictions compared to Logistic Regression.
SUPPLEMENT: Logistic Regression model here
Random Forest to determine AMR
SUPPLEMENT: Complete Random Forest iterations here
The predictive performance of the Random Forest models was evaluated using metadata-only features, including isolation source, top 20 serotypes, and temporal data (month of collection). While individual resistance classes were modeled, the General AMR prevalence model was selected as the primary representative framework for this study. Again, this selection is driven by several key technical and biological considerations. From a public health perspective, predicting overall antimicrobial prevalence offers a more realistic reflection of surveillance goals by accounting for the cumulative resistance burden rather than focusing on isolated, often mutually exlusive phenotypes as observed in the heatmap. This approach also ensures model stability; for example, specific classes like Phenicol yielded extremely poor sensitivity (0.002) due to severe class imbalance, whereas the general model provides a more robust evaluation of the metadata’s predictive signals. Furthermore, the model exhibits a conservative classification profile characterized by high Specificity (>0.97) paired with lower Sensitivity (0.352), establishing a high threshold for “false alarms” that is advantageous for clinical decision-making. Ultimately, a strong ROC AUC of 0.825 confirms that metadata features (such as isolation source, serotype, and temporal data) contain sufficient diagnostic signal to distinguish between resistant and susceptible isolates even in the absence of genomic sequence data.
| Random Forest Model Performance | |||||
| Predicting AMR Classes from Metadata | |||||
| Resistance Class | ROC AUC | Sensitivity | Specificity | Accuracy | Precision |
|---|---|---|---|---|---|
| Tetracycline | 0.837 | 0.354 | 0.976 | 0.908 | 0.642 |
| Aminoglycoside | 0.847 | 0.343 | 0.977 | 0.914 | 0.614 |
| Sulfonamide | 0.850 | 0.336 | 0.977 | 0.923 | 0.574 |
| Beta-lactam | 0.812 | 0.289 | 0.982 | 0.933 | 0.557 |
| Phenicol | 0.808 | 0.002 | 1.000 | 0.959 | 0.444 |
| General AMR | 0.825 | 0.352 | 0.977 | 0.880 | 0.744 |
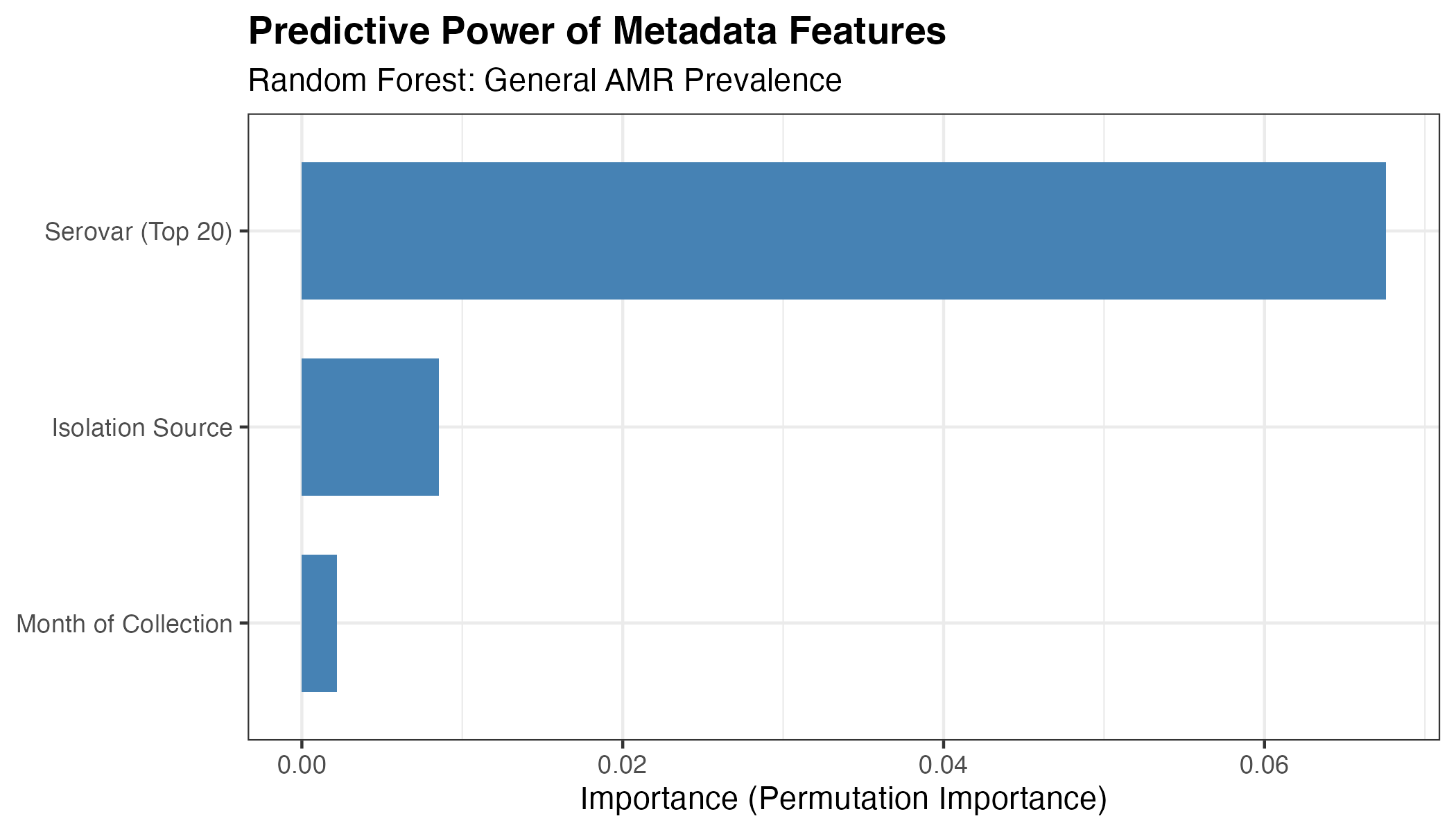
This chart ranks metadata variables based on their contribution to the model’s predictive accuracy. It shows that Serotype is the most influential predictor, followed by Isolation Source, confirming that specific bacterial lineages and their environments are the primary drivers of antimicrobial resistance patterns in this dataset.
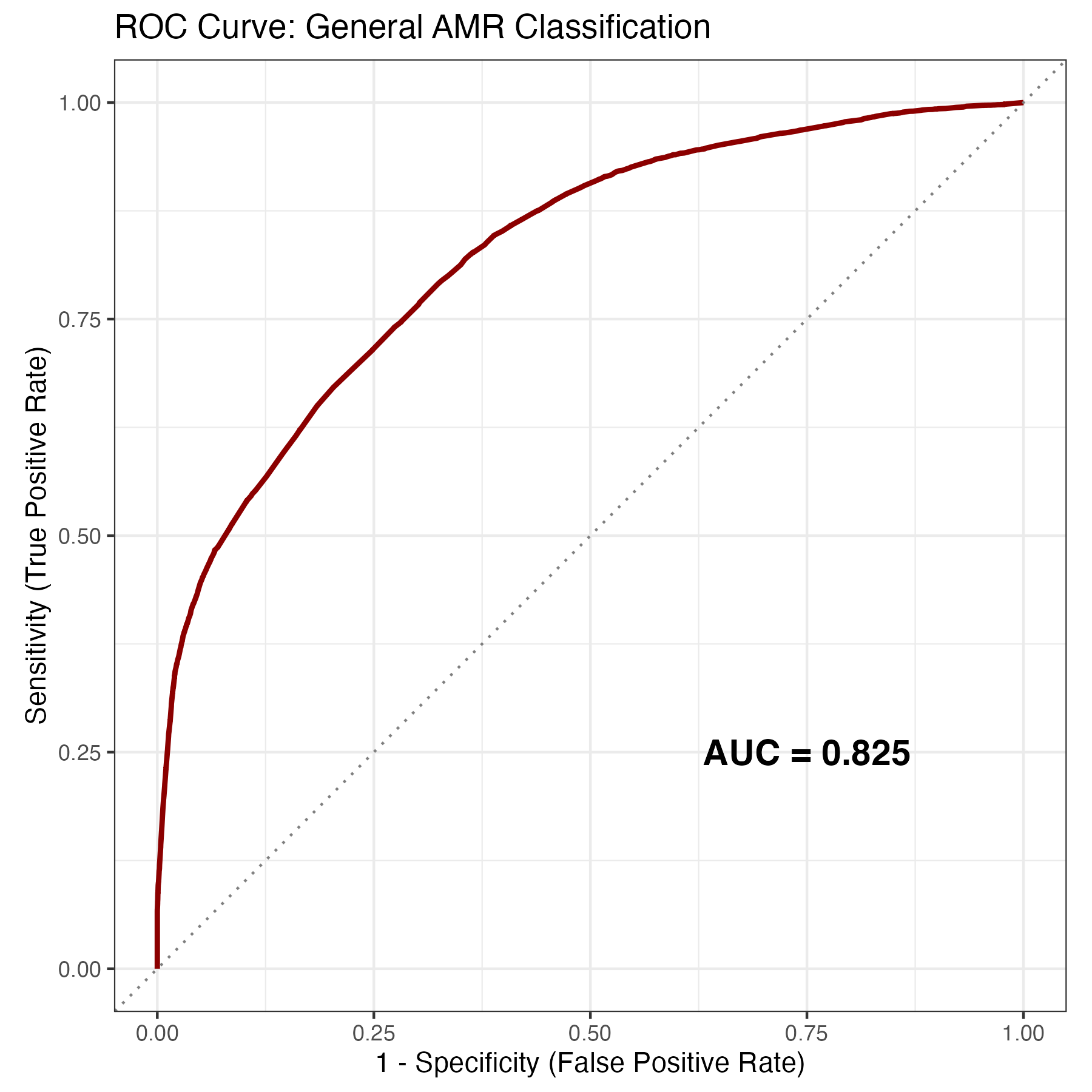
The Receiver Operating Characteristic (ROC) curve illustrates the model’s ability to distinguish between resistant and susceptible isolates across various probability thresholds. With an AUC of 0.825, the curve demonstrates strong discriminative performance, significantly outperforming a random classifier (represented by the diagonal line).
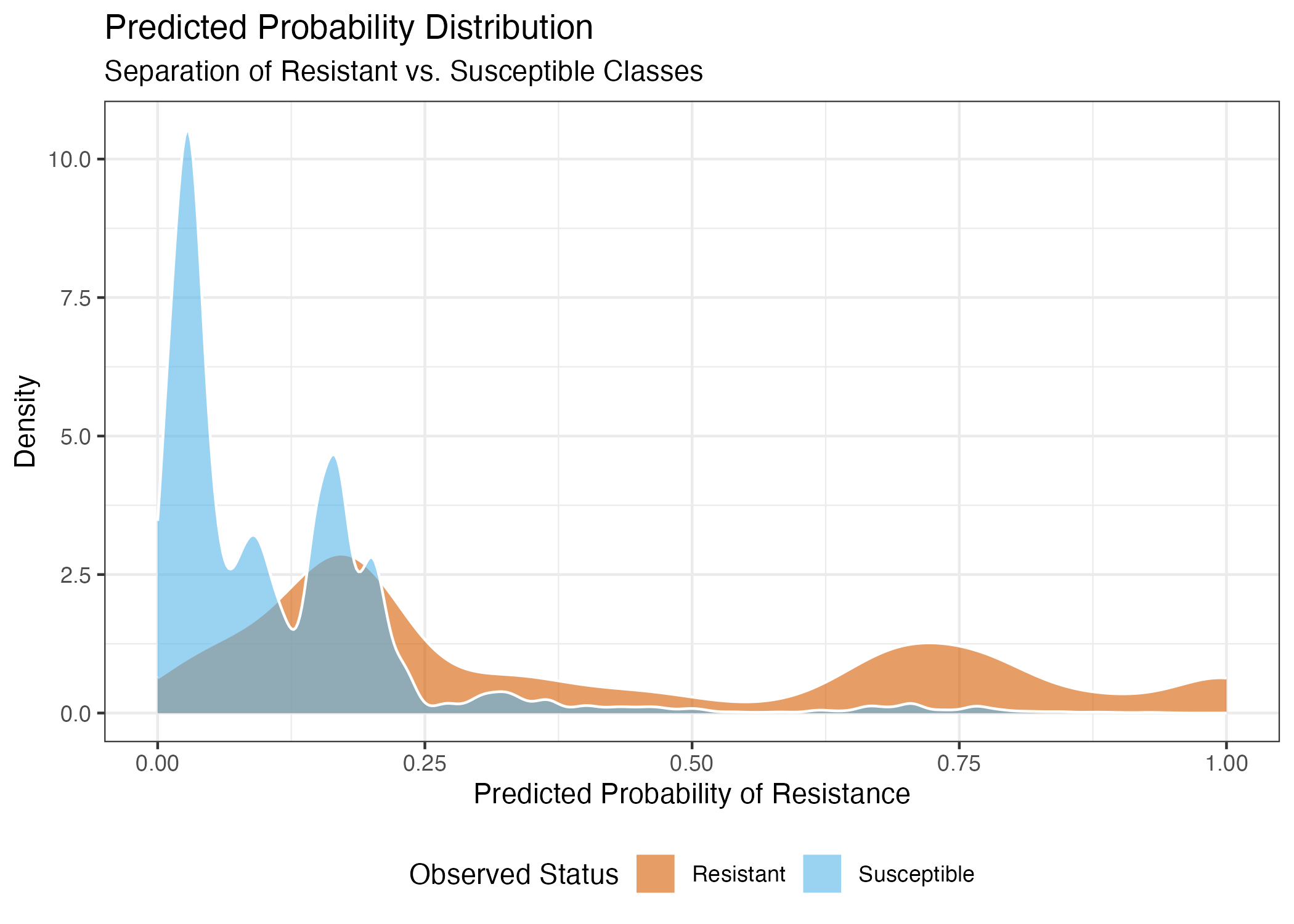
This plot visualizes the distribution of predicted probabilities for both resistant and susceptible classes. The high density of susceptible isolates at very low probability scores explains the model’s exceptional specificity, while the overlapping region near the center highlights the difficulty in achieving high sensitivity using metadata alone.
Quality Control
SUPPLEMENT: Complete Quality Control analysis here
The Random Forest model demonstrated high stability, with 10-fold cross-validation yielding a mean ROC AUC of 0.829 (\(\pm 0.001\) SE). During the honest assessment phase, the model maintained this performance on unseen test data, achieving a final ROC AUC of 0.825 and a sensitivity of 0.352 (Table 5). The confusion matrix (Table 6) illustrates the model’s conservative classification strategy; while it correctly identified 50,650 susceptible isolates with minimal false positives (1,166), it successfully captured roughly one-third of the resistant population using metadata alone. This confirms that while the model is conservative, the resistance predictions it does make are highly reliable.
| Model Stability and Performance | |||
| Phase | ROC AUC | Sensitivity | SE (AUC) |
|---|---|---|---|
| 10-Fold Cross-Validation (Mean) | 0.829 | — | 0.00145 |
| Honest Assessment (Test Set) | 0.825 | 0.352 | — |
| Confusion Matrix | ||
| Evaluation on unseen test data (n = 61,443) | ||
Reference (Truth)
|
||
|---|---|---|
| Actual: Resistant | Actual: Susceptible | |
| Predicted: Resistant | 3391 | 1166 |
| Predicted: Susceptible | 6236 | 50650 |
Discussion
Summary and Interpretation
In this study, we developed and evaluated a metadata-driven machine learning framework to predict antimicrobial resistance (AMR) in Salmonella enterica using a large-scale dataset derived from the NCBI Pathogen Detection repository. Specifically, we implemented a random forest classifier using routinely available epidemiological metadata (i.e. isolation source, serovar, and temporal variables) to predict whether an isolate could exhibit resistance to at least one antimicrobial class.
The model demonstrated strong discriminative performance (ROC AUC = 0.825), indicating that metadata alone contains substantial predictive signal for AMR status. However, performance was asymmetrical: the model achieved very high specificity (97.7%) but relatively low sensitivity (35.2%). This reflects the strong class imbalance inherent to surveillance datasets, where susceptible isolates predominate, and suggests that the model is conservative in assigning resistance labels. From a public health standpoint, this behavior implies that while the model may miss a proportion of resistant isolates, the predictions it does make are highly reliable and have low false-positive rates.
Variable importance analyses revealed that serovar and isolation source were the dominant predictors of AMR status. This finding shows that resistance traits are not randomly distributed but instead cluster within specific lineages and ecological niches,and it is consistent with prior epidemiological and genomic studies showing (Zhang et al., 2015). For example, well-characterized serovars such as Typhimurium and Infantis are frequently associated with multidrug resistance due to the presence of mobile genetic elements and lineage-specific adaptations (Feldgarden et al., 2019; McDermott et al., 2016). Similarly, the higher prevalence of resistance observed in food and animal sources aligns with documented antimicrobial usage patterns in agricultural systems and their role as reservoirs for resistant strains (WHO, 2022; Van Boeckel et al., 2015).
Importantly, this study demonstrates that metadata can serve as a scalable and rapid proxy for AMR risk stratification. While whole-genome sequencing remains the gold standard for identifying resistance mechanisms, it is not always available in real-time surveillance contexts (McDermott et al., 2016). Therefore, metadata-driven models such as the one presented here can function as an early-warning, prioritizing isolates for further genomic characterization and informing targeted interventions (Aslam et al., 2018).
Strengths and Limitations
A major strength of this analysis is the scale and diversity of the dataset, encompassing 245,772 Salmonella isolates collected across multiple sources, and time periods. This large sample size enhances statistical power, improves model generalizability, and enables the capture of real-world heterogeneity in AMR patterns. Additionally, the use of standardized, publicly available data from surveillance systems such as National Antimicrobial Resistance Monitoring System (NARMS) supports reproducibility and external validity.
From a methodological perspective, the use of a random forest algorithm is well-suited for this application due to its ability to model nonlinear relationships and interactions between categorical predictors without requiring extensive preprocessing (Wright & Ziegler, 2017). The implementation within the tidymodels framework, combined with 10-fold cross-validation and a held-out test set, further strengthens the robustness and reproducibility of the findings.
However, several limitations should be acknowledged. First, the reliance on metadata alone inherently constrains predictive performance, particularly sensitivity. AMR phenotypes are ultimately driven by specific genetic determinants, and the absence of genomic features limits the model’s ability to detect resistance mechanisms that are not strongly associated with serovar or source (McDermott et al., 2016). This likely explains the moderate sensitivity observed and highlights the trade-off between scalability and biological resolution.
Second, the dataset exhibits substantial class imbalance, with a predominance of susceptible isolates. While ROC AUC is robust to imbalance, threshold-dependent metrics such as sensitivity are adversely affected. Alternative strategies, such as class weighting, resampling techniques, or threshold optimization, could improve detection of resistant isolates in future work.
Third, potential biases in surveillance data may influence the results. For example, overrepresentation of human clinical isolates and underrepresentation of certain environmental or animal sources could skew both descriptive patterns and model learning. Additionally, metadata variables such as “isolation source” may be inconsistently reported or lack granularity, introducing noise into the predictors.
Finally, the binary definition of AMR (resistant vs. susceptible to ≥1 class) simplifies a complex phenotype. While appropriate for public health screening, this approach does not capture the spectrum of resistance, including multidrug resistance (MDR) or clinically critical resistance profiles (Aslam et al., 2018). Future models could incorporate more nuanced outcome definitions to better reflect clinical risk.
Conclusions
This study demonstrates that routinely collected metadata can be effectively leveraged to predict antimicrobial resistance in Salmonella with strong discriminative performance, even in the absence of genomic data. Key predictors such as serovar and isolation source highlight the structured, non-random nature of AMR across ecological and epidemiological contexts. While the model’s high specificity supports its use as a reliable fast screening in surveillance systems, its moderate sensitivity indicates that metadata alone cannot fully capture the complexity of resistance phenotypes. Overall, integrating metadata-driven approaches with genomic data represents a promising path toward more accurate, scalable, and timely AMR risk assessment in food safety and public health.
References
Aslam, B., Wang, W., Arshad, M. I., Khurshid, M., Muzammil, S., Rasool, M. H., Nisar, M. A., Alvi, R. F., Aslam, M. A., Qamar, M. U., Salamat, M. K. F., & Baloch, Z. (2018). Antibiotic resistance: a rundown of a global crisis. Infection and Drug Resistance, 11, 1645–1658. https://doi.org/10.2147/IDR.S173867
Centers for Disease Control and Prevention. (2024). Clinical overview of Salmonellosis. https://www.cdc.gov/salmonella/hcp/clinical-overview/index.html
Centers for Disease Control and Prevention. (2026). Data and reports | NARMS. https://www.cdc.gov/narms/data/index.html
Feldgarden, M., Brover, V., Haft, D. H., Prasad, A. B., Slotta, D. J., Tolstoy, I., Tyson, G. H., Zhao, S., Hsu, C.-H., McDermott, P. F., Tadesse, D. A., Morales, C., Simmons, B., Tillman, G., Wasilenko, J., Folster, J. P., & Klimke, W. (2019). Validating the AMRFinder tool and resistance gene database by using antimicrobial resistance genotype-phenotype correlations in a collection of isolates. Antimicrobial Agents and Chemotherapy, 63(11), e00483-19. https://doi.org/10.1128/AAC.00483-19
Kuhn, M., & Wickham, H. (2020). Tidymodels: A collection of packages for modeling and machine learning using tidyverse principles. https://www.tidymodels.org
McDermott, P. F., Tyson, G. H., Kabera, C., Chen, Y., Li, C., Folster, J. P., Ayers, S. L., Lam, C., Tate, H., & Zhao, S. (2016). Whole-genome sequencing for detecting antimicrobial resistance in nontyphoidal Salmonella. Antimicrobial Agents and Chemotherapy, 60(9), 5515–5520. https://doi.org/10.1128/AAC.01030-16
National Center for Biotechnology Information. (2026). Pathogen Detection. Retrieved April 27, 2026, from https://www.ncbi.nlm.nih.gov/pathogens/
O’Neill, J. (2016). Tackling drug-resistant infections globally: Final report and recommendations. Review on Antimicrobial Resistance. https://amr-review.org
R Core Team. (2024). R: A language and environment for statistical computing (Version 4.4.x) [Computer software]. R Foundation for Statistical Computing. https://www.r-project.org
Van Boeckel, T. P., Brower, C., Gilbert, M., Grenfell, B. T., Levin, S. A., Robinson, T. P., Teillant, A., & Laxminarayan, R. (2015). Global trends in antimicrobial use in food animals. Proceedings of the National Academy of Sciences, 112(18), 5649–5654. https://doi.org/10.1073/pnas.1503141112
World Health Organization. (2022). Global antimicrobial resistance and use surveillance system (GLASS) report: 2022. https://www.who.int/publications/i/item/9789240062702
World Health Organization. (2024). Antimicrobial resistance. https://www.who.int/news-room/fact-sheets/detail/antimicrobial-resistance
Wright, M. N., & Ziegler, A. (2017). ranger: A fast implementation of random forests for high dimensional data in C++ and R. Journal of Statistical Software, 77(1), 1–17. https://doi.org/10.18637/jss.v077.i01
Zhang, S., Yin, Y., Jones, M. B., Zhang, Z., Deatherage Kaiser, B. L., Dinsmore, B. A., Fitzgerald, C., Fields, P. I., Deng, X., & Salmonella Working Group. (2015). Salmonella serotype determination utilizing high-throughput genome sequencing data. Journal of Clinical Microbiology, 53(5), 1685–1692. https://doi.org/10.1128/JCM.00323-15